Databricks Auto Loader is a prebuilt ETL framework to incrementally and efficiently process new data files as they arrive in cloud storage.
Databricks Auto Loader can load data files from the following cloud storage:
- AWS S3
- Azure Data Lake Storage Gen2
- Azure Blob Storage
- ADLS Gen1
- Google Cloud Storage
- Databricks File System
Databricks Auto Loader can ingest data in the below file format:
- JSON
- CSV
- PARQUET
- AVRO
- ORC
- TEXT
- BINARY FILE
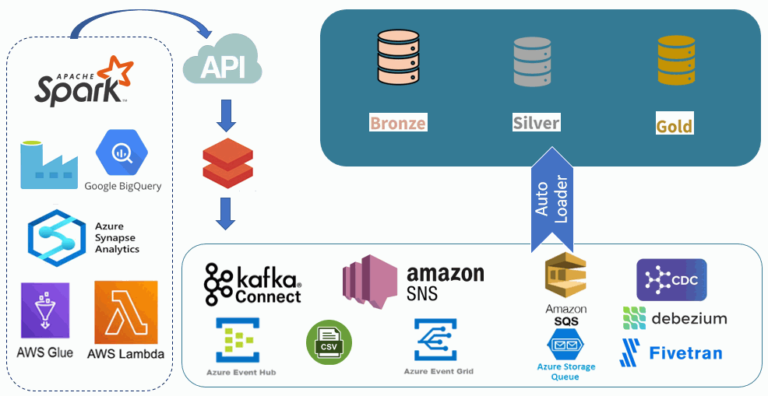
Databricks Auto Loader provides a Structured Streaming source called cloudFiles that automatically processes new files as they arrive in a configurable input directory. Databricks Auto Loader supports Python and SQL in Delta Live Tables.
We can use Databricks Auto Loader to process billions of files to ingest data in cloud storage. Auto Loader scales to support near real-time ingestion of millions of files per hour.
In Delta Live Tables, we can use Databricks Auto Loader to ingest data incrementally by writing a few lines of declarative Python or SQL.
Databricks Auto Loader Features
- Incrementally and efficiently process new data files as they arrive in cloud storage
- File Notification mode enables event-driven ingestion
- Automatically infer the schema of incoming files. Superimpose with Schema Hints.
- Automatic schema evolution
- Rescue Column’s Data
Databricks Auto Loader Syntax for DLT
Python and SQL syntax is used to support Auto Loader in Delta Live Tables.
Python Syntax for Databricks Auto Loader:
The below example uses the Databricks Auto Loader to create a dataset from a CSV file using Python syntax:
@dlt.table
def Products():
return (
spark.readStream.format(“cloudFiles”)
.option(“cloudFiles.format”, “csv”)
.load(“/dbc-ds/Masters/Products/”)
)
We can use the Schema to define the columns manually in a declarative statement:
@dlt.table
def Products():
return (
spark.readStream.format(“cloudFiles”)
.schema(“id INT, ProductName STRING, Description
STRING, text STRING”)
.option(“cloudFiles.format”, “parquet”)
.load(“/dbc-ds/Masters/data-001/Products-parquet”)
)
SQL Syntax for Databricks Auto Loader:
The below example uses the Databricks Auto Loader to create a dataset from a CSV file using SQL syntax:
CREATE OR REFRESH STREAMING LIVE TABLE Products
AS SELECT * FROM cloud_files(“/dbc-ds/Masters/Products/”, “csv”)
We can use the Schema to define the columns manually in a declarative statement:
CREATE OR REFRESH STREAMING LIVE TABLE Products
AS SELECT *
FROM cloud_files(
/dbc-ds/Masters/data-001/Product-parquet”,
“parquet”,
map(“schema”, “id INT, ProductName STRING, Description STRING, text STRING”)
)