What will you learn from here?
In this article, you will learn how star schema gets implemented in a real-world scenario. we will be providing you with the step by step implementation that will be easy and understandable for all newbies out there who are willingly ready to dive into the data science field.
Prerequisites for the implementation
- Familiarity with jupyter notebook.
- Basic knowledge of python and DataFrames
- Familiarity with by PySpark
- Basic star schema overview.
What is Star Schema?
A star schema is a database organizational style that employs a single large fact table to store transactional or measurable data and one or smaller dimensional tables to hold qualities about the data. It is designed for usage in a data warehouse or business intelligence. Since the fact table occupies the center of the logical diagram and the small dimensional tables branch off to create the points of the star, it is known as a star schema.
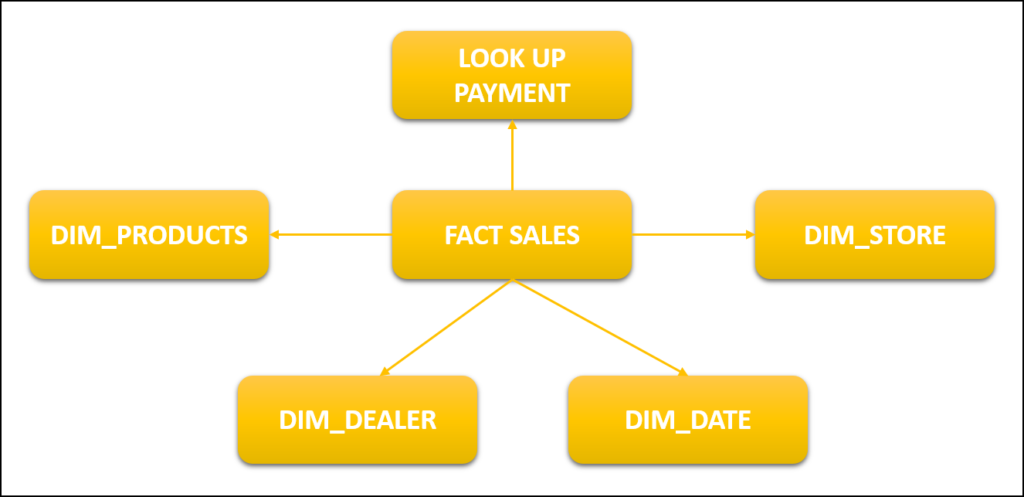
Conceptual star schema diagram explanation
In the diagram shown below, you can see we have one fact which is linked to other dimensions.
- Fact: A fact is something in which we include calculated quantities along with dimension keys associated with that fact.
- Dimensions: Dimension is those that stores detailed data of a particular key that is associated with that row.
- Lookup: Lookup tables contained fixed values that are less likely to get updated e.g. payment methods cash payment or online transaction
We are going to implement the star schema through PySpark. As we know for implementation we need dummy data. You can find the dummy we will be used by downloading it from here: Excel Data Sheet.
In this excel sheet, we have an ice cream data set. first, we will be analyzing the data in jupyter notebook. For this purpose:
- Part 1: we will read the excel file and will store it in a data frame and then we will perform a basic analysis of data i.e. checking if we have null values or what kind of columns are present in our dataset.
- Part 2: we will be performing operations and step-by-step functionalities to make our dimensions and facts from the above diagram by using our dataset.
Implementing star schema in jupyter notebook Part(1)
Finding Pyspark
#necessory
import findspark
findspark.init()
from pyspark.sql import SparkSessionTo build a spark session, we first imported the SparkSession module after importing the Findspark module. we will call findspark.init() constructor.
from pyspark.sql import SparkSession
The Dataset and DataFrame API can be built using a spark session. Additionally, a SparkSession can be used to build a DataFrame, register it as a table, run SQL over tables, cache a table, and read a parquet file.
Calling Libraries
#Libraries
import pandas as pd
from pyspark.sql.functions import row_number,lit ,desc, monotonically_increasing_id
from pyspark.sql.functions import desc, row_number, monotonically_increasing_id
from pyspark.sql.window import Window
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField,IntegerType, StringType , DateType,FloatTypethese are the libraries that we will be using while manipulating our DataFrame to implement the star schema
# May take a little while on a local computer
spark = SparkSession.builder.appName("Basics").getOrCreate()It is used to retrieve an already-existing SparkSession or, in the absence of one, to construct a new one using the builder’s settings.
df = pd.read_excel('C:/Users/mycomputer/Downloads/IcecreamDataset.xlsx')In this code, we have declared df means DataFrame and stored the path of our excel file which we downloaded earlier to read it. Till now you are able to read the excel file and stored the result in df DataFrame.
Basic Transformation over Dataframe
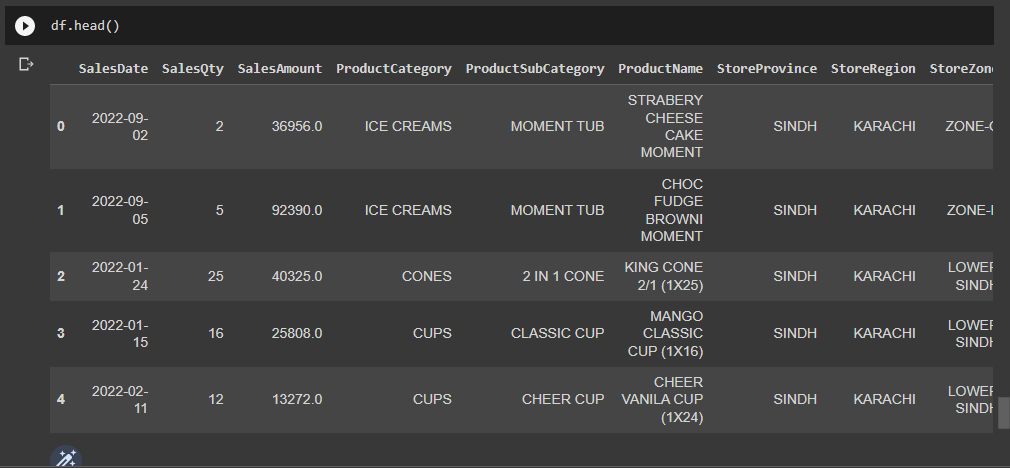
df.head()Here we are reading our data and what it looks like. The following picture will tell how our data will look like up till now
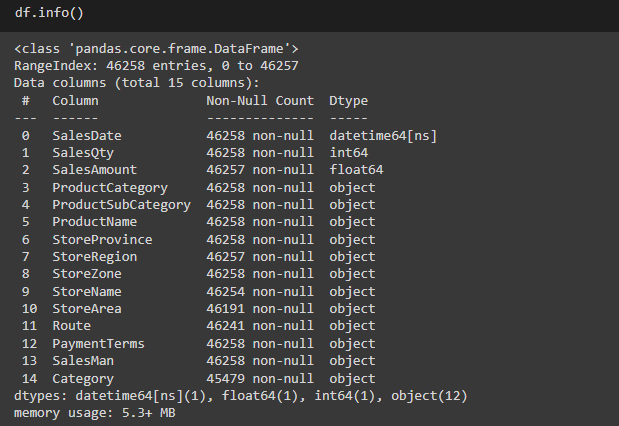
df.info()we will check the basic overview of our DataFrame through this command you can see the output here:
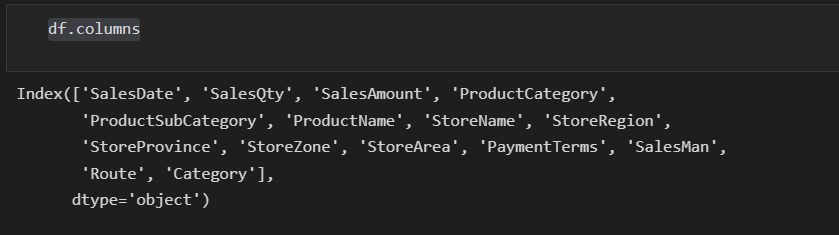
df.columnsIn this statement, we will see how many columns we have in our DataFrame.
For further implementation for dimension and fact table do check our article i.e. Implementing star schema in jupyter notebook part(2) . Do check our previous article to set up the jupyter and PySpark environment

