ETL, or extract, transform, and load, is a method of integrating data that gathers information from several sources into a single, consistent data store that is then loaded into a data warehouse or other destination system.
ETL was introduced as a way for integrating and loading data for computation and analysis as databases gained in popularity in the 1970s, eventually taking over as the main technique for processing data for data warehousing projects.
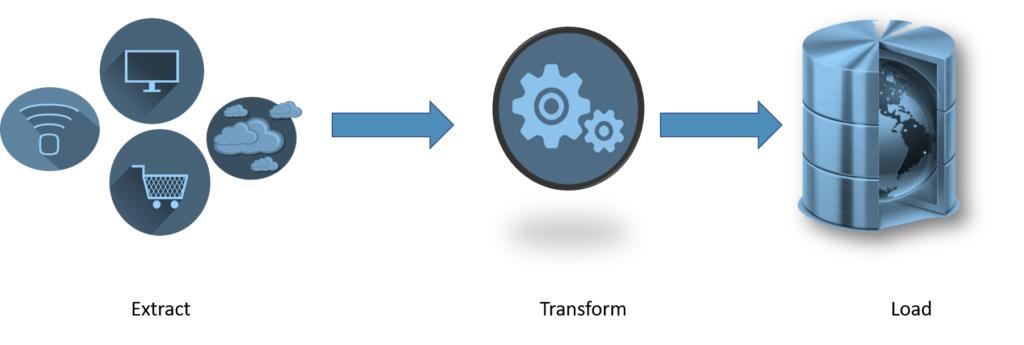
ETL serves as the building block for workstreams in data analytics and machine learning. By a set of business standards, ETL cleans and arranges data in a way that satisfies particular business intelligence requirements, such as monthly reporting, but it can also handle more advanced analyses that can enhance back-end operations or end-user experiences. An organization frequently uses ETL to:
- Take data out of old systems.
- Cleanse the information to increase its accuracy and uniformity.
- Fill the target database with data.
ETL vs ELT
The order of operations between ETL and ELT differs, which is the most noticeable distinction. Instead of transferring the data to a staging area for transformation, ELT loads the raw data directly to the target data store to be converted as necessary.
Although each approach has pros and cons, they both require a range of data repositories, including databases, data warehouses, and data lakes. ELT is especially helpful for large, unstructured datasets since it allows for source-direct loading. Given that data extraction and storage don’t require much in the way of planning, ELT may be more suitable for big data management. On the other hand, the ETL process starts out needing more definition. It is necessary to identify particular data points for extraction and any relevant “keys” to combine data from various source systems. The business rules for data transformations still need to be created after that job is finished. Usually, this job can be dependent on the information needed for a specific kind of data analysis will be used to decide how much of the data should be summarized. While ELT has gained popularity as cloud databases have been used, it has drawbacks because it is a more recent procedure, meaning that best practices are still being developed.
How ETL works?
Understanding what occurs at each stage of the process is the simplest approach to comprehending how ETL functions.
Extract:
Data extraction involves copying or exporting raw data from source sites to a staging place. Teams of data managers can extract information from a range of structured and unstructured data sources. These sources range from but are not restricted to:
- SQL or SQL software
- Systems for CRM and ERP
- A flat file
- Web page
Transform:
The staging area is where the raw data is processed. For its intended analytical use case, the data is changed and consolidated in this place. The following tasks may be involved in this phase:
- The data is filtered, cleaned, duplicated, validated, and authenticated.
- Utilizing the raw data to do computations, translations, or summaries. This may entail modifying text strings, changing row, and column headings to ensure uniformity, converting money or other units of measurement, and more.
- Conducting audits to verify data compliance and quality.
- Deleting, encrypting, or safeguarding information under the control of authorities such as the government or industry.
- Data formatting to create tables or combine tables by the destination data warehouse’s structure.
Load:
The converted data is sent from the staging area into the target data warehouse in this final stage. This often entails the initial loading of all data, recurring loading of incremental changes to the data, and, less frequently, full refreshes to completely remove and replace all data in the warehouse. Most businesses that employ ETL have automated, well-defined, batch-driven processes that are continuous. ETL typically happens after business hours, when activity on the source systems and the data warehouse is at a minimum.
The benefits and challenges of ETL
Before importing the data into a new repository, ETL systems do data cleansing to increase quality. While other data integration techniques, such as ELT (extract, load, transform), change data capture (CDC), and data virtualization, are used to integrate progressively larger volumes of changing or real-time data streams, ETL, a time-consuming batch operation, is frequently advised for creating smaller target data repositories that require less frequent updating.
ETL and other data integration methods
There are additional strategies that are used to streamline data integration procedures in addition to ETL and ELT. A few of these are:
- Only the altered source data is identified, captured, and transferred to the target system using Change Data Capture (CDC). CDC can be used to cut down on the number of resources needed for the ETL “extract” step. It can also be used on its own to instantly move transformed data into a data lake or other repository.
- Real-time or batch data replication transfers changes in data sources to a central database. Data integration techniques frequently include data replication. In actuality, disaster recovery backups are the ones that are most frequently created.
- Without physically copying, altering, or loading the source data to the target system, data virtualization uses a software abstraction layer to produce a unified, integrated, fully usable picture of the data. Without the cost and complexity of developing and administering separate platforms for each, data virtualization functionality enables an organization to generate virtual data warehouses, data lakes, and data marts from the same source data for data storage. Although it can be used in conjunction with ETL, data virtualization is increasingly viewed as a viable replacement for ETL and other physical data integration techniques.
- Just as it sounds, stream data integration (SDI) continually consumes data streams in real time, transforms them, and loads the transformed data streams to a target system for analysis. The term “continuously” is crucial here. SDI continuously integrates data as it becomes available, as opposed to integrating snapshots of data gathered from sources at a specific moment. To support analytics, machine learning, and real-time applications for enhancing customer experience, fraud detection, and other purposes, SDI enables data storage.
You can also view and read our other article related to data science, big data, and their implementation here:

